
Be More Google: Using Big Data to Shape the Learner Experience
May 6, 2016

It won’t come as any great surprise to you that I think Google’s Self-Driving car is pretty clever.
But I don’t think it’s clever because of the Self-Driving part. Making cars autonomous was always going to be possible; the rules of the road are very well codified, which makes the ‘systemisation’ of driving plausible.
No, what I find really clever is how the car gets better with experience. How it learns.
When I passed my driving test and got let loose on the roads for the first time I was, without doubt, a terrible driver. Insurance companies were right to charge me a huge premium. I was a liability. I crashed in the first month.
Over time and with experience I have become more aware of my surroundings and the potential hazards that I face as a driver. But it’s taken years, probably a good decade of experience, before I stopped being a liability. It may have been possible to speed that process up if I took advanced training or if I drove professionally. But I think for most people years of experience are probably required to become a predictable asset to other drivers on the road.
Exploiting Big Data, the Google Way
When 10,000 of Google’s Self-Driving cars take to the road they will be fairly naïve on day one. But on day two, presuming each car gets an hour of use, each car will be 10,000 hours more experienced than it was on the first day. That’s a decade of driving experience in a day. It isn’t just a one-to-one relationship between a car and its experiences. These cars are networked together, learning from each other’s experiences.
It isn’t realistic to expect the product to be perfect right away. But it is realistic to expect it to improve dramatically faster than a human. This is what makes the Google Self-Driving car really clever in my book. That it learns.
Big Data is looking like the buzz phrase of 2016 when it comes to Learning Technology. It is the power of ‘Big Data’ that Google exploits to make its Self-Driving car really clever. But this is Google. They have the resources to exploit Big Data. And they actually have the means to capture the data in the first place. Realistically, what can your organisation hope to do to exploit Big Data like Google exploits Big Data?
Well, here’s the sad news. You probably can’t. Most examples of ‘Big Data’ in the online learning world don’t really reach the threshold for ‘bigness’. We’re not talking a few thousand data points here; we’re talking hundreds of millions, if not billions.
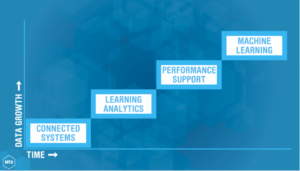
The 4 Stages to Realising the Potential of Big Data in Learning
For some organisations there will rightly be a question as to whether or not their company is of sufficient scale to ever be a ‘big data’ generator. But even if the answer to that is ‘no’ there are still steps on the ladder to really clever that every organisation can take, big or small. How far you can go will depend on your dataset.
I imagine the potential for Big Data in four stages. With each stage the requirement for more data increases. Without the prerequisite amount of data in place you will run the risk of spurious assumptions. Just because a Fox runs out in front of your Self-Driving car once, doesn’t mean it should always travel at 20mph. You need to control for the outliers.
Stage 1: Connected Systems
The first step is one that most of the organisations I talk to are suffering. They simply do not have a set of connected systems in place. One process cannot talk to another. The LMS doesn’t talk to the CMS. The Intranet doesn’t connect to the LMS. Attendance is on an Excel spreadsheet. The HR system talks to nothing.
This is unbelievably common. As we look to blend more forms of learning as part of the work + learning process, so we start to see gaps appear in basic assessments of competence and readiness. It might be that the workforce is trained but we just can’t prove it.
If we could get our systems talking a common language when it comes to training activity not only could we solve the issues we face in assessing readiness, but we could also lay the foundation for our machine-learning infrastructure.
Step one; connect the systems. Enter xAPI.
xAPI is a standard way of talking about our learning experiences, using data. It isn’t a technology in and of itself; it is a set of rules that systems can adopt in order to increase the level of inter-operability that exists between each other.
It is within the gift of your company’s procurement process to start requiring vendors to provide inter-operable solutions. Application Programming Interfaces, or APIs, are the usual way in which systems make this happen. Each API comes with a documented method of using the API, such that other systems can use it.
But when you deal with tens of systems, each with a different API, it becomes a huge amount of work to get the systems connected. xAPI takes this a step further, specifying a series of generic APIs that are well suited to learning systems. If you insist your vendors must have this in place before you bring them in, you know that your ecosystem will be interoperable. It will connect.
Part of adopting xAPI is the introduction of a single source of record; a database that centralises data from each system and makes it available to every other system. This is called the Learning Record Store (LRS) and Learning Locker is an example of this type of software. With your systems connected via the Learning Locker you can start thinking about the next step on the ‘Big Data’ ladder, Learning Analytics.
Stage 2: Learning Analytics
Learning Analytics is the use of data to create actionable insights that seek to improve learning and working outcomes.
The lowest hanging fruit here is to understand which of our learning experiences are effective for our learners. The holy grail of Learning Analytics in the workplace is the explicit linking of learning and performance. Data that shows training actually making a difference to the business bottom-line.
We’ve seen some interesting results from our use of xAPI-based Learning Analytics. For example, we know now that the length of a video has a very strong correlation with the length of time a learner spends on the page. When we show a 4-minute video, folks dwell on the page for an average of 9.27mins. When we show an 8-minute video, dwell time drops to less than 30 seconds.

Data Source: Learning Locker
We know that when we send out emails to people activity does actually increase; in fact it doubles:
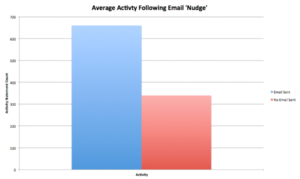
Data Source: Learning Locker
And we know that longer comments are generally more insightful than short ones when it comes to a social learning experience (more on this in a moment):
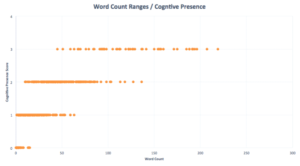
Data Source: Learning Locker
We have been able to draw some big ‘bottom-line’ conclusions in specific cases. For example, our work with Villeroy & Boch won a Gold award from the Learning & Performance Institute after we showed a link between completion of a cross-selling course and an uplift in retail sales (+31%!).
Learning Analytics data can lead you to some interesting ideas, but you need to get out and actually do the work to prove the correlation / causations that you see. It is not enough to show a trend line on a graph. You need to question people who actually take these experiences to find out what they do and why they do it. Only then can you move on to the next step, Performance Support.
Stage 3: Performance Support
There is a lot of talk about the need for learning as ‘performance support’. Helping individuals at the moment of need through ‘just-in-time’ learning. But how do you actually do it, technically speaking?
I believe the first two steps, Connected Systems and Learning Analytics, lay the groundwork that you will need to build on to deliver true performance support.
Learning Analytics can help you to tease out the potential relationships between learning and performance. Now you need to model this relationship. Initially this will be very explicit. You can program systems with ‘If This, Then That’ (IFTTT) logic. For example, our Learning Analytics might show a strong relationship between passing an exam and attaining a strong overall performance level. So you create the following model:
“If the learner fails the test three times in a row, send an email to them with some extra hints and tips”.
Now that’s obviously very simplistic and doesn’t need a complex system to accomplish. But this is the concept that underpins adaptive learning systems that we hear so much about. These organisations have modeled the relationships between learner behaviours and outcomes. And, based on these models, they can recommend different paths depending on performance.
These models begin as simple ‘IFTTT’ concepts and, over time, join together to make complex maps of typical paths to success. This, to me, is what Performance Support should look like: A system that gives appropriate help, or signposts where appropriate help can come from, at the moment of need.
Stage 4: Machine Learning
Our models will start off life fairly simple. But they, like us, can learn from experience. If we keep sending the help email from the above example but it makes no difference to a certain group of learners performance there is little point in us continuing with the action. We must try something different. Our models must learn from their experiences. This, at its most simple, is Machine Learning.
At this point it all becomes quite meta; your xAPI-based systems sending more xAPI statements back to themselves to understand if the interventions the system has made have been positive or negative. But this ability to modify future actions based on past experience is the hallmark of Artificial Intelligence (AI). An example in the public eye recently is the AlphaGo system from Google. Built to play the ancient board game ‘Go’, AlphaGo was successful in consistently defeating one of the highest ranked players in the world.
We’ve seen feats like this before; Deep Blue and Gary Kasparov for example. But this time it was actually different. Go, unlike Chess, cannot be brute-forced. It is not possible to calculate all of the possible outcomes of a game and to choose the optimum strategy: It is said that there are more possibilities in a game of Go than there are atoms in the Universe.
Instead, AlphaGo used its experience to beat its opponents. Having initially created some models of play from historical records, AlphaGo then underwent a process of playing itself. Millions of times. It went from being a good Amateur in late-2015 to being the best in the world by early-2016. Each time it played itself it came to memorise which strategies lead to failure (a loss) and which resulted in a success (a win). It learnt just like any other player, from experience. The difference was that AlphaGo could do this millions of times in short succession and it had better recall than its human counterparts.
What Does the Future Learner Experience Look Like?
Organisations throw around buzzwords like ‘adaptive’ and ‘personalised’ without much insight into how these states are actually achieved. But by starting small and connecting your systems together with a common data format we can see a path towards realising the hype.
Truth be told, there is some doubt in my mind that individual organisations can achieve all four steps on their own. Machine Learning works on a scale and time that doesn’t really suit training needs. It seems unlikely that you will ever have enough data to model these relationships with certainty in every circumstance. It seems even less likely that you’ll be given the time to gather the data, analyse it, model it and make it self-learn.
But it is likely that vendors, independent of any one customer, can come to these conclusions given their scale. To make the future learner experience a reality, organisations must be prepared to work with the vendors of these new technologies. The best results will be found where historical data is available to help these systems learn from past experiences.
And this means that starting step one – Connecting Systems – is something to be done today if you want to leverage these future learning experiences tomorrow.
Got a learning problem to solve?
Get in touch to discover how we can help
